中国科学技术大学潘建伟、陆朝阳等组成的研究团队与中科院上海微系统所、国家并行计算机工程技术研究中心合作,构建了 76 个光子的量子计算原型机
“九章”,实现了具有实用前景的“高斯玻色取样”任务的快速求解。根据现有理论,
该量子计算系统处理高斯玻色取样的速度比目前最快的超级计算机快一百万亿倍(“九章”一分钟完成的任务,超级计算机需要大约一亿年)。等效地,
其速度比去年谷歌发布的 53 个超导比特量子计算原型机“悬铃木”快一百亿倍。这一成果使得
我国成功达到了量子计算研究的
第一个里程碑:量子计算优越性(国外也称之为“量子霸权”),相关论文于 12 月 4 日以“First Release”形式在线发表于国际学术期刊
Science。
本文转载自公众号“墨子沙龙”
撰文 林梅
在气象工程师白冰被追捕的路上,他认识了同样被追捕的宋诚。白冰神秘地拿出一只箱子, “这是一台超弦计算机,是我从气象模拟中心带出来的,你说偷出来的也行,我全凭它摆脱追捕了”。
这个情节来自科幻作家刘慈欣的中短篇小说《镜子》。在故事里,白冰偷出来的这台机器是一台拥有了几乎无限运算和存贮能力的计算机,它不仅能模拟气象这种复杂过程,还可以模拟整个宇宙的演化。只要给定每个粒子的初始条件,整个宇宙的运行就像镜子一样清楚地展现,准确无误。
借由主人翁白冰的口述,作者表达过他对计算的理解:用模拟方式为一个鸡蛋建立数学模型,就是将组成鸡蛋的每一个原子的状态都输入模型的数据库,当这个模型在计算机中运行时,如果给出的边界条件合适,内存中的那个虚拟鸡蛋就会孵出小鸡来,而且那只内存中的虚拟小鸡,与现实中的那个鸡蛋孵出的小鸡一模一样,连每一根毛尖都不会差一丝一毫!如果这个模拟目标比鸡蛋再大些呢?大到一棵树,一个人,很多人;大到一座城市,一个国家,甚至大到整个地球?如果模拟的对象是整个宇宙又会怎么样?
现实的物理系统究竟能不能被计算机模拟?这种猜想绝不仅限于科幻作家的小说中,也存在于严肃的学术讨论和哲学思考里。比如,计算机领域中非常著名的扩展的丘奇-图灵论题(extended Church-Turing thesis)就认为,任何物理系统都可以被经典图灵机有效模拟。
但是,随着人们对微观世界的深入理解,扩展的丘奇-图灵论题开始被质疑,尤其是随着量子力学的发展,更多人意识到,实际的量子过程太过复杂,如果用经典计算模拟量子过程,需要的时间可能会呈指数增长。也就是说,有效计算是不可能的。1980 年代,费曼提出,模拟量子过程,必须放弃经典计算的老套路,用量子材料造一台新式机器,来自然地解决这些问题。
没错,就是量子计算机。
经典计算和量子计算的区别在哪里呢?
对于经典计算机来说,每个比特要么代表 0,要么代表 1,这些比特就是信息,而对这些信息运算,实际上就是用电路构建一些逻辑门,完成“与”、“非”、“或”以及更复杂的操作。而量子计算,则是利用量子天然具备的叠加性,施展并行计算的能力。每个量子比特,不仅可以表示 0 或 1,还可以表示成 0 和 1 分别乘以一个系数再叠加,随着系数的不同,这个叠加的形式可能性会很多很多,它会产生什么效果呢?
我们以两个比特举例,对于经典的两比特来说,在某一时刻,它最多只能表示 00、10、01、11 这四种可能性的一种;而量子计算由于叠加性,可以写成
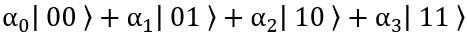
也就是说,它可以同时蕴含有四种信息状态。这种叠加性意味着,随着比特数增加,信息的存储量和运行速度会指数增加,经典计算机将望尘莫及。
|量子计算优越性的实现是一场持久战
基于量子的叠加性,许多量子科学家认为,量子计算机在特定任务上的计算能力将会远超任何一台经典计算机。2012 年,美国物理学家 John Preskill 将其描述为“量子计算优越性”或称“量子霸权”(quantum supremacy)。科学家们预计,当可以精确操纵的量子比特超过一定数目时,量子计算优越性就可能实现。
如果有一个特定的问题,量子计算需要一个小时,经典计算需要上亿年,量子计算优越性便得以实现,扩展的丘奇-图灵论题也会被动摇,因为那就证明了,有些过程,经典计算是无法有效模拟的。
从科学家对量子计算优越性的观点来看,有两个关键点,一是操纵的量子比特的数量,二是操纵的量子比特的精准度。只有当两个条件都达到的时候,才能实现量子计算的优越性。如图一所显示的,左下角的范围(紫色)代表的是操纵的量子比特数目和精准度都不够的情形,这时是不可能在跟经典计算的PK中胜出的,科学家们在尽量朝着右上方(绿色)努力。而位于中间的部分(蓝色),则可以用来在短期内实现一些应用上的突破。
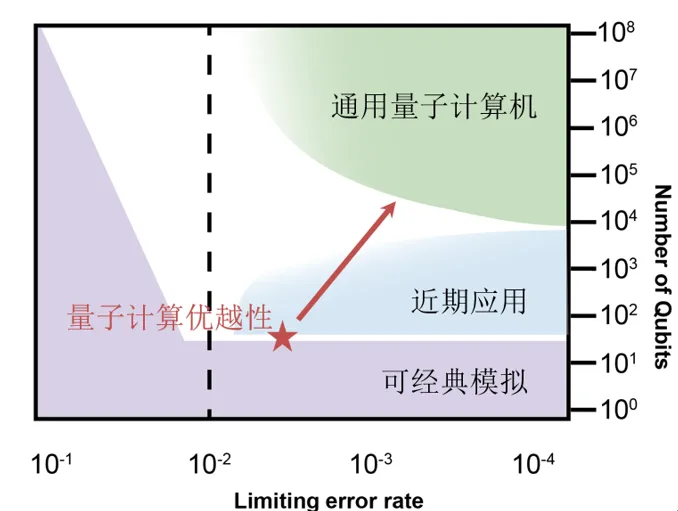
图一 量子计算优越性与操纵量子比特的关系
去年 10 月,谷歌在量子计算方面十多年的布局终于有了里程碑式的表现——国际权威学术杂志 Nature 以“Quantum supremacy using a programmable superconducting processor”为题,刊发了谷歌的科研工作,谷歌据此宣布实现了量子计算优越性。
根据谷歌的论文,该团队选取的用来展示量子计算优越性的特定任务是一种叫做“随机线路采样(Random Circuit Sampling)”的任务。一般来说,选取这种特定任务的时候,需要经过精心考量,该任务最好比较适合已有的量子体系,同时对于经典计算来说很难模拟。这个“随机线路采样”任务就是如此。谷歌团队在一个包含 53 个可用量子比特的可编程超导量子处理器上运行“随机线路采样”,用约 200 秒的时间进行了 100 万次采样,同时他们还利用当时世界排名第一的超级计算机 Summit 进行了一个比较,他们预计,同样的任务,Summit 需要算上一万年。“200 秒”PK“一万年”,该团队宣称这意味着量子计算优越性成为现实。
谷歌的这项工作很快引发了学术界的争议。因为量子计算和经典计算的竞争是一个长期的动态过程,虽然人们操纵量子比特的数量和精准度在不断提高,但是经典计算的算法和硬件也在不断优化,超算工程的潜力更是不可小觑。比如,IBM 就宣称,实现 53 比特、20 深度的量子随机线路采样,经典模拟完全可以只用两天多时间,甚至还可以更好,也许未来何时,经典模拟在这个任务上就能超过谷歌团队的量子计算机。所以,客观看来,量子计算和经典计算的算力之争,可能是一个长期 battle 的过程,未来一段时间,我们可能会见证两者卯足了劲儿“秀肌肉”的精彩打擂。
|深孚众望的玻色采样任务
在用来展示量子计算优越性的特定任务中,还有一种任务被科学家寄予厚望——玻色采样(Boson Sampling)。
玻色采样是一种采样任务,2010 年由当时在 MIT 的 Scott Aaronson 和 Alex Arkhipov 首次提出。为了说明这是一个怎样的问题,我们先来回顾儿时的一个游戏——高尔顿板。
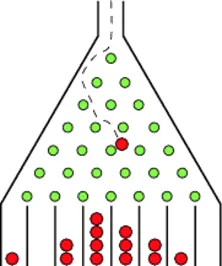
图二 高尔顿板示意图
高尔顿板问题是由英国生物统计学家高尔顿提出来的,像图二展示的那样,小球从上端的口落下,每经过一个钉板,都有一半的可能从左边走,一半的可能从右边走,最后,当很多小球扔下去后,下面格子里的小球分布会呈现一定的统计规律。这个模型也被直观的用来展示中心极限定理。
而我们所说的玻色取样问题就是一种量子版的“高尔顿板”问题。就像图三展示的那样,小球变成了光子,钉板变成了分束器,若干个光子进入网格之后,经过分束器组成的干涉仪,最终分别在哪些出口被探测到,记录下来,就是一个采样。积累之后,光子数也会有一个分布。每一种采样结果都对应一个概率。全部可能的采样结果就构成输出态的态空间。

图三 玻色取样问题
但是,玻色采样问题比高尔顿板问题复杂得多。为什么呢?因为这个网格的每个节点都是一个小分束器,如果相遇在这个节点上的光子是全同的,那么几个光子接下来怎么走,不仅仅是一个“随机”的概率问题,而且还是个“复杂”的概率问题——这个概率与分束器的参数有关,也与光子本身的相位有关。如果我们用矩阵来表示这个过程的话,可以理解为:这个大网格就是一种变换关系,把入口的光子分布变换成出口的光子分布,这个变换关系必须要写成一个复数矩阵。2010 年,Scott Aaronson 和 Alex Arkhipov 从理论上证明,n 光子玻色取样的分布概率正比于 n 维矩阵积和式(Permanent)的模方,这对经典算法来说是 #P-complete 困难的问题,随着光子数的增加,求解步数呈指数增长。对于这样的问题,量子计算机在中小规模下就有可能打败超级计算机。自此,“玻色采样”问题被用来挑战量子计算优越性。
自玻色采样提出,世界上陆续有很多个小组从实验上挑战和验证玻色采样。2013 年,国际上四个研究小组同时实现 3 光子的原理验证性玻色采样。从原理上说,这个实验大致的过程是:单光子源不断地发出单光子,经过一个多模式干涉仪,最后在各个出口用探测器探测。但是,由于技术的限制,真正的单光子源很难做出,这些小组都采用了赝单光子源(赝单光子源时不时会冒出来多光子的成分),干涉网络的性能又不怎么好,这些因素制约着玻色取样的高效率大规模实现。
当然,有一些小组也提出或实现过一些好的方案来解决赝单光子源所带来的不可拓展性。比如,2014 年 A. P. Lund 等人提出散粒玻色采样(scattershot boson sampling)实验方案,但是由于采用的是自发参量下转换(SPDC)光源,这种概率性的光源产生单光子的效率非常低,所以实验上一直没有真正实现 3 个以上光子的玻色采样。更重要的是,这些实验相比经典计算机并未展示出任何量子优越性。
看来,这事要想弄成,必须得在单光子源和干涉仪上下功夫,单光子源的单光子性、全同性和提取效率要好,干涉仪效率要高,波包重叠性也要好。于是,人们想到了量子点光源,希望用量子点光源来产生真正的单光子。
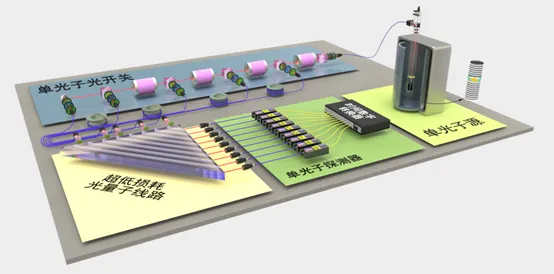
图四 超越早期经典计算机的光量子原型机
2017 年,中国科大潘建伟、陆朝阳团队同样把目光聚焦到了量子点光源。值得一提的是,他们用的是一种共振激发的量子点光源,能产生确定性的高品质单光子,此外,他们自主设计研发了高效率的线性光学网络。在这种装备武装下,实验上首次实现 5 光子玻色采样。采样率是之前所有实验的至少 24 000 倍,相比于早期的经典计算机 ENIAC 和 TRADIC,计算能力具有 10-100 倍的提升。图五展示了这次实验和此前其他玻色采样实验计算能力的比较。可以看出,这次的结果不仅远好于国际同行,更是第一次超越了早期的经典计算机。这是人类历史上首次量子计算机和经典计算机的同台竞赛,标志着量子计算机的研究不再是发文章,而是可以制造真正的仪器执行具体的算法,在量子计算的发展中具有重要意义。
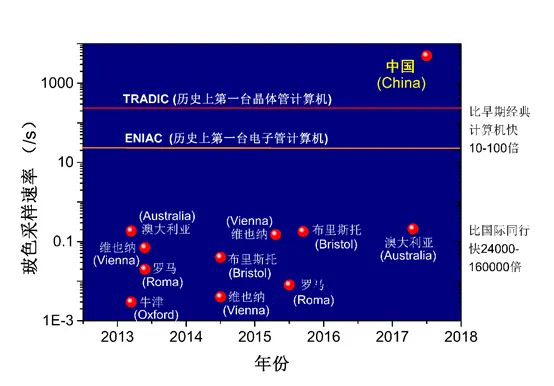
图五 2017 年以及此前所有玻色采样的计算能力比较
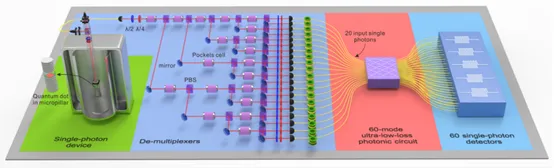
图六 20 光子输入、60 模式输出的玻色采样
2019 年,该团队又将这种方案向前推进一步——他们将 20 个光子输入 60 个入口、60 个出口模式的干涉线路,实验中,出口最多探测到了 14 个光子。这个工作同时在光子数、模式数、计算复杂度和态空间四个关键指标上都大幅超越之前的国际记录。
但是,实验中的低效率始终是量子计算可扩展的拦路虎。尽管科研人员已经将单光子的效率尽量做了提升,但是每次采样任务,需要的是对所有出口光子的符合测量,我们可以想象一下,符合后的计数率会随着光子数的增加指数下降,再想扩展这个实验的规模,遇到了瓶颈。
|玻色采样峰回路转
那么短期内,我们证明量子计算优越性还有希望吗?答案是肯定的。2017 年,由 Hamilton 等人提出的高斯玻色采样(Gaussian Boson Sampling)方案提供了很好的解决办法。高斯玻色采样充分利用 PDC 源的高斯性质,并利用可以确定性制备的单模压缩态(SMSS)作为输入的非经典光源。2018 年,Quesada 等人将这种方案进行了简化,他们证明,只需要采取阈值探测的方法,即探测到一个及以上光子都记作 1,这时的输出分布与一个被称为 Torontonian 的矩阵函数有关。Torontonian 是 Hafnians 的无限和,对于经典算法来说,计算它同样是一个 #P 困难的问题。
关于压缩态光,你可能并不陌生。在引力波的探测中,就用到了压缩态光。压缩态光是一种量子光源,它超越散粒噪声极限的噪声压制本领,令其在引力波探测中起到了关键作用。在玻色采样中,采用单模压缩态光源,是为了显著提高效率。区别于单光子光源“一个一个”走出来的状态,单模压缩态光源可以看做是“一团一团”走出来。每激发一次,可以产生很多对相干的光子,一起进入干涉网络。足够高的效率,为量子比特的扩展提供了可能。
近期,中国科大潘建伟、陆朝阳团队就采用压缩态光源,实现了这种尝试。
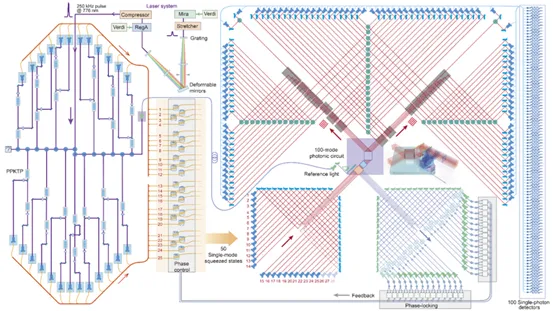
图七 高斯玻色取样量子计算原型机“九章号”
他们利用 50 个单模压缩态,输入一个 100 个入口、100 个出口的线性光学网络,最后在网格出口处安置了单光子探测器来采样。得益于团队此前在玻色采样方面的积累,他们的技术在各个指标上都具有显著的优势。光源方面,他们拥有国际上唯一同时具备高效率、高全同性、极高亮度和大规模扩展能力的量子光源,而且该团队还具有最大规模(100×100)的干涉技术,还能同时做到全连通、随机矩阵、相位稳定、波包重合好(>99.5%)、通过率高(>98%)。此外,中科院上海微系统所研制的高性能超导单光子探测器也扮演了重要角色。

图八 “九章号”部分实景
不同于标准玻色采样,高斯玻色采样需要高精度的锁相技术。为什么这点至关重要呢?
我们可以回忆一下经典物理里干涉需要哪些条件。比如我们比较熟悉的光波、水波,想要产生稳定的干涉条纹,有一个重要条件就是两束波的相位差恒定。量子的干涉也类似,如果每一路的光相位总是抖动,彼此之间相位差就会不稳定,就观测不到稳定的采样结果。
在这次实验中,每路单模压缩光进入干涉网络之前,要各自经过 2 米自由空间和 20 米光纤,所谓保持相位锁定,也就是保证这个路径的光程恒定。科学家们采取“缺啥补啥”的策略,让同源的若干路激光分别去走压缩态光所走的路程,并与一个标准参考激光进行比较(通过干涉的方法),实时监测每一路与标准参考光的相位差,并进行相应的调整。在精密微妙的操控下,2 米自由空间 + 20 米光纤光程抖动保持在 25 纳米之内,这相当于 100 公里的距离误差小于一根头发丝。
在最终的采样结果里,该团队成功构建了 76 个光子 100 个模式的高斯玻色采样量子计算原型机。科学家给它起名叫“九章”。
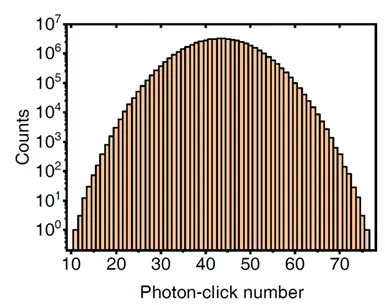
图九 最终探测到的光子数分布
|“九章”VS“富岳”,“九章”VS“悬铃木”
之所以将这台新量子计算机命名为“九章”,是为了纪念中国古代最早的数学专著《九章算术》。《九章算术》是中国古代张苍、耿寿昌所撰写的一部数学专著,它的出现标志中国古代数学形成了完整的体系,是一部具有里程碑意义的历史著作。而这台叫做“九章”的玻色采样新机器,同样具有重要的里程碑意义。
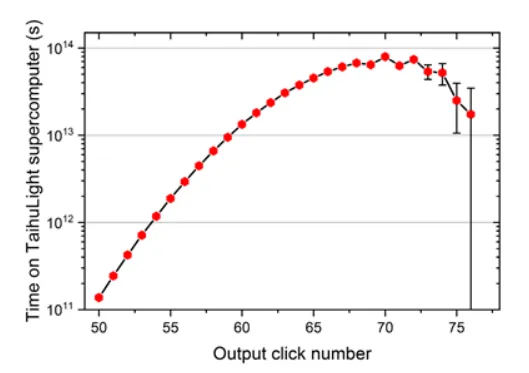
图十 “九章”相对于太湖之光的优势比较
根据目前最优的经典算法,“九章”花 200 秒采集到的 5000 个样本,如果用我国的“太湖之光”,需要运行 25 亿年,如果用目前世界排名第一的超级计算机“富岳”,也需要 6 亿年。这样的优势十分明显。我们可以等效地对比去年谷歌发布的 53 比特量子计算原型机“悬铃木”:对于“悬铃木”来说,200 秒完成的任务,超算 Summit 需要 2 天,考虑 Summit 和富岳的算力差距,“九章”等效地比“悬铃木”快 100 亿倍。
作为对比,我们可以回顾一下“悬铃木”其他方面的情况。谷歌 53 比特随机线路取样实验中,量子优越性是依赖于样本数量的。虽然采集100万个样本时,“悬铃木”需要 200 秒,超算 Summit 需要 2 天,量子计算相比于超级计算机有优越性;但如果采集 100 亿个样本的话,经典计算机仍然只需要 2 天,可是“悬铃木”却需要 20 天才能完成这么大的样本采样,量子计算反而丧失了优越性。而对于高斯玻色采样问题,量子计算优越性不依赖于样本数量。此外,在态空间方面,“九章”也以输出量子态空间规模达到 1030 的优势远远优于“悬铃木”,“悬铃木”输出量子态空间规模是 1016,而目前全世界的存储容量是 1022。而且,“九章”运行的温度也远没有“悬铃木”那样苛刻,除探测部分需要 4K 的低温以外,其他部分都是在常温下运行的。
“九章”的出色表现,牢固确立了我国在国际量子计算研究中的第一方阵地位,为未来实现可解决具有重大实用价值问题的规模化量子模拟机奠定了技术基础。
量子计算机的研制已成为世界科技前沿的最大挑战之一,作为欧美各发达国家角逐的焦点,可以预见不会止步于此。对于量子计算机的研究,本领域的国际同行公认有三个指标性的发展阶段,其中第一个阶段是发展具备 50-100 个量子比特的高精度专用量子计算机,对于一些超级计算机无法解决的高复杂度特定问题实现高效求解,实现计算科学中“量子计算优越性”的里程碑。此次“九章”的研制成功,就是这重要的第一个阶段胜利。在这之后,科学家还会致力于研制可相干操纵数百个量子比特的量子模拟机,用于解决若干超级计算机无法胜任的具有重大实用价值的问题(如量子化学、新材料设计、优化算法等);最后,大幅度提高可操纵的量子比特的数目(百万量级)和精度(容错阈值>99.9%),研制可编程的通用量子计算原型机。
在可以预见的未来,不断优化的经典计算和不断进取的量子计算,还将在算力之争上持续 battle。
值得一提的是,“九章”的研制成功,不仅是实现了“量子计算优越性”的里程碑,也为第二步——解决若干超级计算机无法胜任的具有重大实用价值的问题提供了潜在的前景。因为,“九章号”量子计算原型机所完成的高斯玻色取样算法在图论、机器学习、量子化学等领域具有潜在应用。科学家设想,这些对于经典算法模拟起来异常困难的问题,如果开发一个 GBS 量子计算机,以此作为一个特殊用途的光子平台,让分子振动、机器学习这些复杂过程以玻色采样的方式高速运行一下,就可以很好地来研究这些现实世界中很重要的应用。除了秀肌肉以外,解决现实问题,其实也是科学家们研发量子计算机的初衷呀。
说了这么多,来见识一下我们的“九章号”的真容,看看量子力学支配下的光学魅影。





(摄影:马潇汉、梁竞、邓宇皓)
国际著名量子光学专家、罗马大学教授 Fabio Sciarrino 在玻色采样领域深耕多年,他对“九章”的表现和中国团队的工作给出了一个全面精准的评价,一起来感受一下大牛孩童般的兴奋吧。
(感谢陆朝阳教授、王辉老师对本文的指导与帮助)
本文转载自公众号“墨子沙龙”(ID:MiciusSalon),原标题为“经典和量子的算力之争:中国科学家实现‘量子计算优越性里程碑’”。授权或合作请联系微信号 MICIUS-SALON 或 mozi@ustc.edu.cn。
 您现在的位置:
您现在的位置: